# Indexing
# Elasticsearch
Elasticsearch is a highly scalable open-source full-text search and analytics engine. It allows you to store, search, and analyze big volumes of data quickly.
TIP
The default Mimetypes list which content is indexed by default: text/., application/ms. , application/vnd.* , application/xml , application/excel , application/powerpoint , application/xls, application/ppt , application/pdf , application/xhtml+xml,application/javascript , application/x-javascript , application/x-jaxrs+groovy , script/groovy this list can be re-defined in exo.properties file by adding the following parameter
exo.unified-search.indexing.supportedMimeTypes=NEW-LIST
TIP
Max allowed Mimetype file size to be indexed is by default : 20 MB, a new Max size value can be re-defined in exo.properties file by adding the following parameter
exo.unified-search.indexing.file.maxSize=xx
This chapter covers the following topics:
Elasticsearch Configuration: Configuration for Elasticsearch .Elasticsearch Indexing architectureIndexing Architecture
# Elasticsearch Configuration
With the external mode, eXo Platform connects to the external Elasticsearch node or cluster.
TIP
Please check the recommended version of Elasticsearch in eXo supported environments (opens new window).
Some parameters should be configured for the external mode through exo.properties file:
exo.es.search.server.url: The URL of the node used for searching.exo.es.search.server.username: The username used for BASIC authentication on the Elasticseach node used for searching.exo.es.search.server.password: The password used for BASIC authentication on the Elasticseach node used for searching.exo.es.index.server.url: The URL of the node used for indexing.exo.es.index.server.username: The username used for the BASIC authentication on the Elasticsearch node used for indexing.exo.es.index.server.password: The password used for the BASIC authentication on the Elasticsearch node used for indexing.
You can find more details about the above parameters, default values and description in Properties reference.
# Elasticsearch Indexing architecture
# Indexes
An index in Elasticsearch is like a table in a relational database. It has a mapping which defines the fields in the index, which are grouped by multiple type. An index is a logical namespace which maps to one or more primary shards and can have zero or more replica shards.
Learn more about indexing in Elasticsearch here (opens new window).
With eXo Platform and Elasticsearch, an index is dedicated to each application (Wiki, Calendar, Documents...). All the application data (for example wiki application data: wiki, wiki page, wiki attachment) will be indexed in the same index.
# Sharding
A shard is a single Lucene instance. It is a low-level worker unit which is managed automatically by Elasticsearch.
Learn more about Sharding in Elasticsearch here (opens new window).
In eXo Platform with Elasticsearch:
- Sharding will only be used for horizontal scalability.
- eXo Platform does not use routing policies to route documents or documents type to a specific shard.
- The default number of shards is 5: the default value of Elasticsearch.
- This value is configurable per index by setting the parameter
shard.numberin the constructor parameters of the connectors.
# Replicas
- Each index can be replicated over the Elasticsearch cluster.
- The default number of replicas is 1 (the default value of Elasticsearch) which means one replica for each primary shard.
- This value is configurable per index by setting the parameter
replica.numberin the constructor parameters of the connectors.
# JCR
Managing a large data set using JCR in a production environment sometimes requires special operations with indexes stored in a file System. One such maintenance operation, called "re-indexing" consists of recreating an index by re-scanning the data. You usually need to re-index when you observe odd behaviors or many errors in the logs. There can be various reasons to re-index. For example, hardware faults, hard restarts, data corruption, migrations, or simply after an upgrade to enable new features. A re-index is usually requested on server startup or in runtime. In eXo Platform, there are two kinds of indexes: Elasticsearch and JCR. They have different re-indexing procedures which will be the purpose of the next sections. Match what's below in this chapter:
Elasticsearch re-indexingHow to perform Elasticsearch re-indexing.JCR Asynchronous re-indexingHow to perform JCR re-indexing.
# JCR asynchronous re-indexing
# Indexing on start-up
The easiest way to trigger a JCR re-indexing at start-up is to stop the server and manually remove the indexes that need to be recreated. When the server starts, the missing indexes will be detected and the necessary re-indexing operations will begin.
JCR supports direct RDBMS re-indexing. This is usually faster than ordinary re-indexing and can be configured via the rdbms-reindexingQueryHandler parameter set to true .
The start-up is usually blocked until the indexing process finishes.Block time depends on the amount of persisted data in the repositories. You can resolve this issue by using an asynchronous approach to start-up indexation which involves on performing all operations on indexes in the background without blocking the repository. This approach is controlled by the value of the async-reindexing parameter in QueryHandler configuration. Setting async-reindexing to true activates asynchronous indexation and makes JCR start without active indexes. But you can still execute queries on JCR without exceptions and check the index status via QueryManagerImpl:
boolean online =
((QueryManagerImpl)Workspace.getQueryManager()).getQueryHandeler().isOnline();
An OFFLINE state means that the index is currently recreating. When the state has been changed, the corresponding log event is printed. From the start of the background task, the index is switched to OFFLINE* with the following log event:
[INFO] Setting index OFFLINE (repository/production[system]).
When the process has been finished, two events are logged:
[INFO] Created initial index for 143018 nodes (repository/production[system]).
[INFO] Setting index ONLINE (repository/production[system]).
These two log lines indicate the end of process for the workspace given in brackets. Calling isOnline() as mentioned above will also return true.
# Hot asynchronous workspace re-indexing via JMX
TIP
First of all, you can not launch hot re-indexing via JMX if the index is already in offline mode. This means that the index is currently invoked in some operations, like re-indexing at start-up, copying in cluster to another node or something else. It is also important to note that hot asynchronous re-indexing via JMX and "on start-up" re-indexing are completely different features. You can not perform start-up re-indexing using the getHotReindexingState command in the JMX interface. However there are some common JMX operations:
- getIOMode: return the current index IO mode (READ_ONLY / READ_WRITE), belongs to clustered configuration states.
- getState: return the current state (ONLINE / OFFLINE).
Some hard system faults, errors during upgrades, migration issues and some other factors may corrupt the index. End customers would most likely want the production systems to fix index issues during runtime without delays and restarts. The current version of JCR supports the Hot Asynchronous Workspace Reindexing feature. It allows administrators to launch the process in background without stopping or blocking the whole application by using any JMX-compatible console.(See the JConsole in action screenshot below).
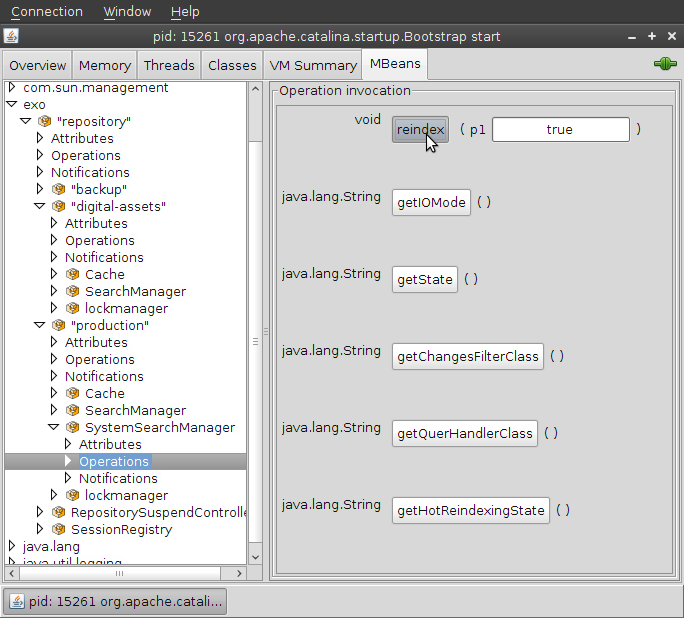
The server can still work as expected while the index is being recreated. This depends on the flag "allow queries", which is passed via the JMX interface to invoke the re-indexing operation. If the flag is set to "true", the application is still working. However, there is one critical limitation that you must be aware of. If the index is frozen while the background task is running, queries are performed on the index present at the moment of task start-up and data written into the repository after start-up will not be available through the search until the process finishes. Data added during re-indexation is also indexed, but will be available only when the task is done. To resume, JCR takes the "snapshot" of indexes on the asynchronous task start-up and uses it for searches. When the operation finishes, the stale indexes are replaced with the new ones, including the newly added data. If the allow queries flag is set to false, all queries will throw out an exception while the task is running. The current state can be acquired using the following JMX operation:
- getHotReindexingState(): return information about latest invocation: start time, if in progress or finish time if done.